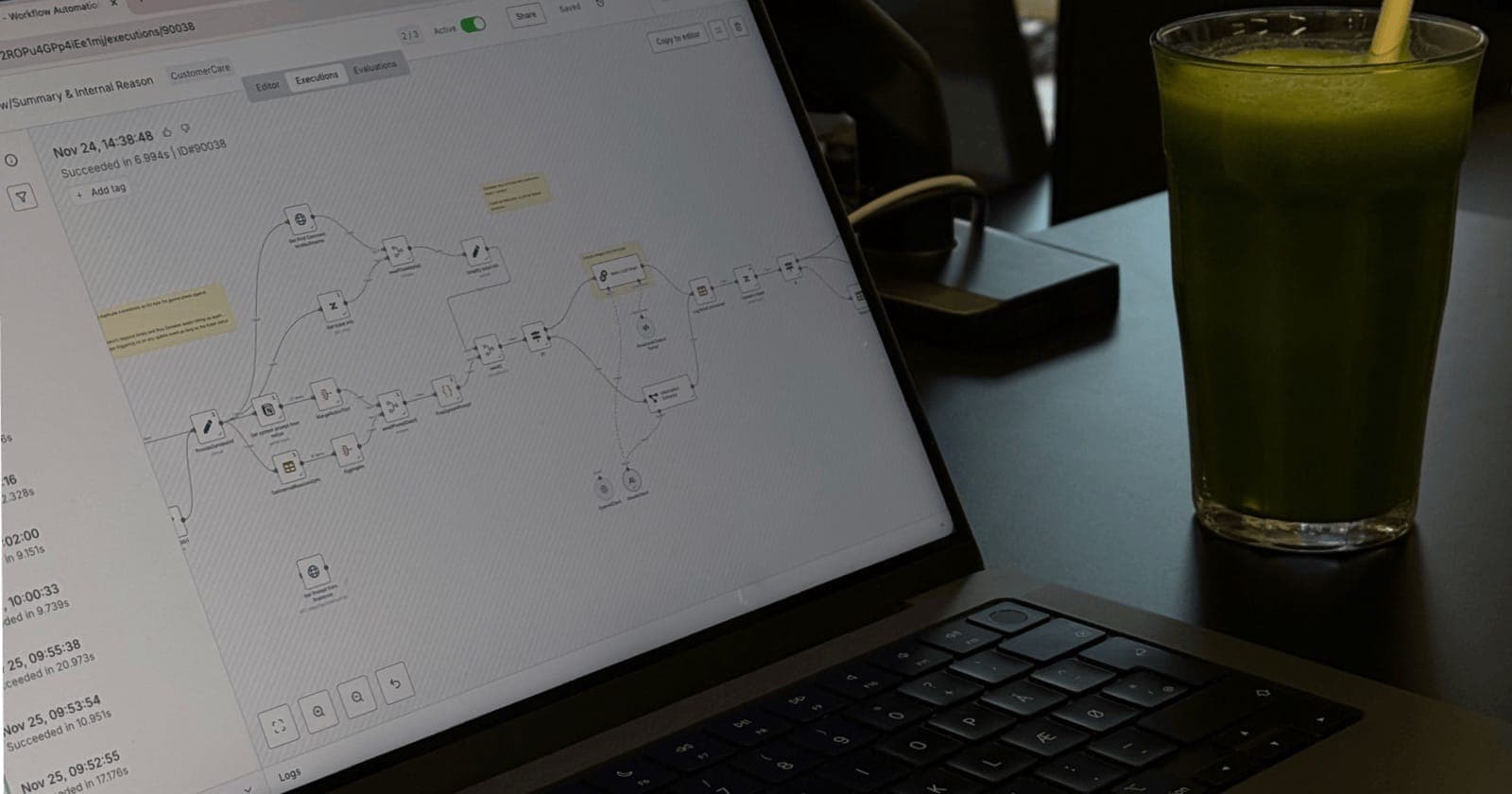
How to get JSON from video? Aka, transcribe any video file on your computer
Steal my Warp workbook to quickly get transcripts without leaving your terminal
I've discovered coding back in 2013 and three years later I spent all my summer building my first Laravel app which is still in production by the non-profit I've built for.
Now I'm struggling to find the balance between enjoying the power of "I can build this myself" and not chocking myself to death trying to build everything myself.
As it is common for developers to be less articulate, I decided to leverage writing about my endeavours, to keep me up.
History
Two weeks ago I found myself sharing my side project where I transcribe a whole dozen of videos into a list of JSON files containing word-level transcripts. Everyone who has been into the AI news since end of 2022 will probably know about Whisper. It's one of the wildest value drops for everyone.
Solving GPU (for Whisper) runtime
However running Whisper model locally can get quite demanding, can be slow or impossible given on the hardware. I am a big fan of high accuracy, high value and high speed. That means I want the large model and low speed.
Initially I have used Modal.com for running my Python code. It worked well but I don't want to maintain python. I want to be as simple as possible. In winter I came across Replicate.com (there's at least half a hundred of hosted providers like that, I'm trying to keep my bookmarks updated). It offers turian/insanely-fast-whisper-with-video, which in short is much faster version Whisper runtime. OpenAI tends to provide a working but not optimised code.
Solving file hosting
It didn't take long for me to try it using cURL and jq to have the transcript. But there was one problem. Many of the files are on my laptop. Such as a meeting I've just had at Flügger. I need it available on some url. There are data protections and again, I wanted to keep as simple as possible. One thing that we all love and use is S3 storage. Lucky me, I came to notice that Cloudflare's R2 (their S3 offering) has finally added the support.
So I created a very convenient bucket called tmp and a few rules to delete files after one day if path prefix matches s3://tmp/1d/ . Boom. Now I can use CLI to copy paste the file into private bucket that cleanses itself and get a signed URL, that is publicly accessible and private.
Reusable script
My terminal, Warp.dev, after updating itself popped up with a new notebook announcement. I must have gotten lucky again. Instead of writing a shell script, now I could create a Python like notebook that I can add comments and remind my future self what the heck I'm doing here. Sometimes it's scary how quickly I can forget certain commands and how they work, if I haven't thought about them for a few weeks.
The code
You may download this code as a Warp notebook from here:
https://gist.github.com/flexchar/0a9c6ecf0c1b9c2592e45af78c30cb23
or right in your holy shell
wget https://gist.githubusercontent.com/flexchar/0a9c6ecf0c1b9c2592e45af78c30cb23/raw -O video-to-json.md
Prerequisites
This script uses
s5cmdas an s3 client which can be installed usingbrew install s5cmd, or equivalent on other systems.This script assumes you have
r2alias set for
r2='s5cmd --credentials-file ~/.config/s3/r2-config.cfg --endpoint-url https://{your bucket id}.r2.cloudflarestorage.com'
- Replicate token set as an environment variable
export REPLICATE_API_TOKEN=
Process
- Upload video to S3 on Cloudflare R2 bucket. This will create as web accessible link so we don't have to kill ourselves uploading the file directly. The bucket files are not browsable by public so they're still private.
S3_PATH="s3://tmp/7d/{{destination_name}}"
r2 cp --sp {{source_path}} $S3_PATH
Couple notes: Our tmp bucket is configured with two rules that delete files that start with either 1d and 7d prefix respectively. The rule of course matches the prefix duration. As the bucket name implies, this bucket shouldn't be used for anything that should be persistent. Each file is wiped on its 30 days year old birthday, aka, it gets removed. Please see section Object lifecycle rules in your bucket settings.
- After uploading, get a publicly accesible link - that is presign the URL.
SIGNED_URL=$(r2 presign --expire 1h $S3_PATH)
echo $SIGNED_URL
- Submit to Replicate
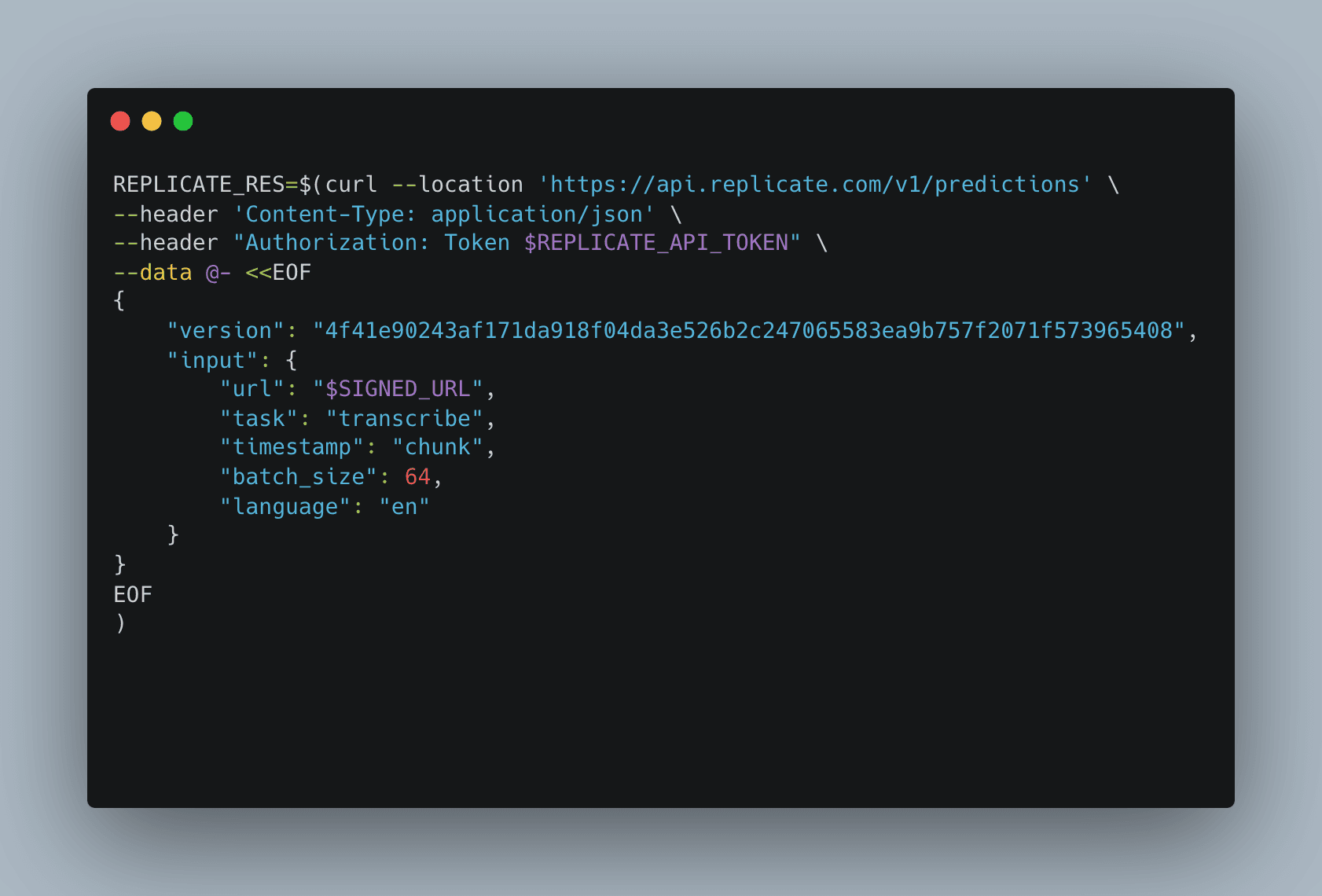
REPLICATE_RES=$(curl --location 'https://api.replicate.com/v1/predictions' \
--header 'Content-Type: application/json' \
--header "Authorization: Token $REPLICATE_API_TOKEN" \
--data @- <<EOF
{
"version": "4f41e90243af171da918f04da3e526b2c247065583ea9b757f2071f573965408",
"input": {
"url": "$SIGNED_URL",
"task": "transcribe",
"timestamp": "chunk",
"batch_size": 64,
"language": "en"
}
}
EOF
)
echo $REPLICATE_RES | jq
WHISPER_ID=$(echo $REPLICATE_RES | jq -r '.id')
echo $WHISPER_ID
This is a cold-started ML endpoint. It may take up to 3 minutes until your transcript is ready.
You could completely add a loop that calls endpoint and checks for status, every 5 seconds, make sure to not DDoS them.
- Get the results using the id in the response
OUTPUT_FILE="{{output_filename}}.json"
echo $OUTPUT_FILE
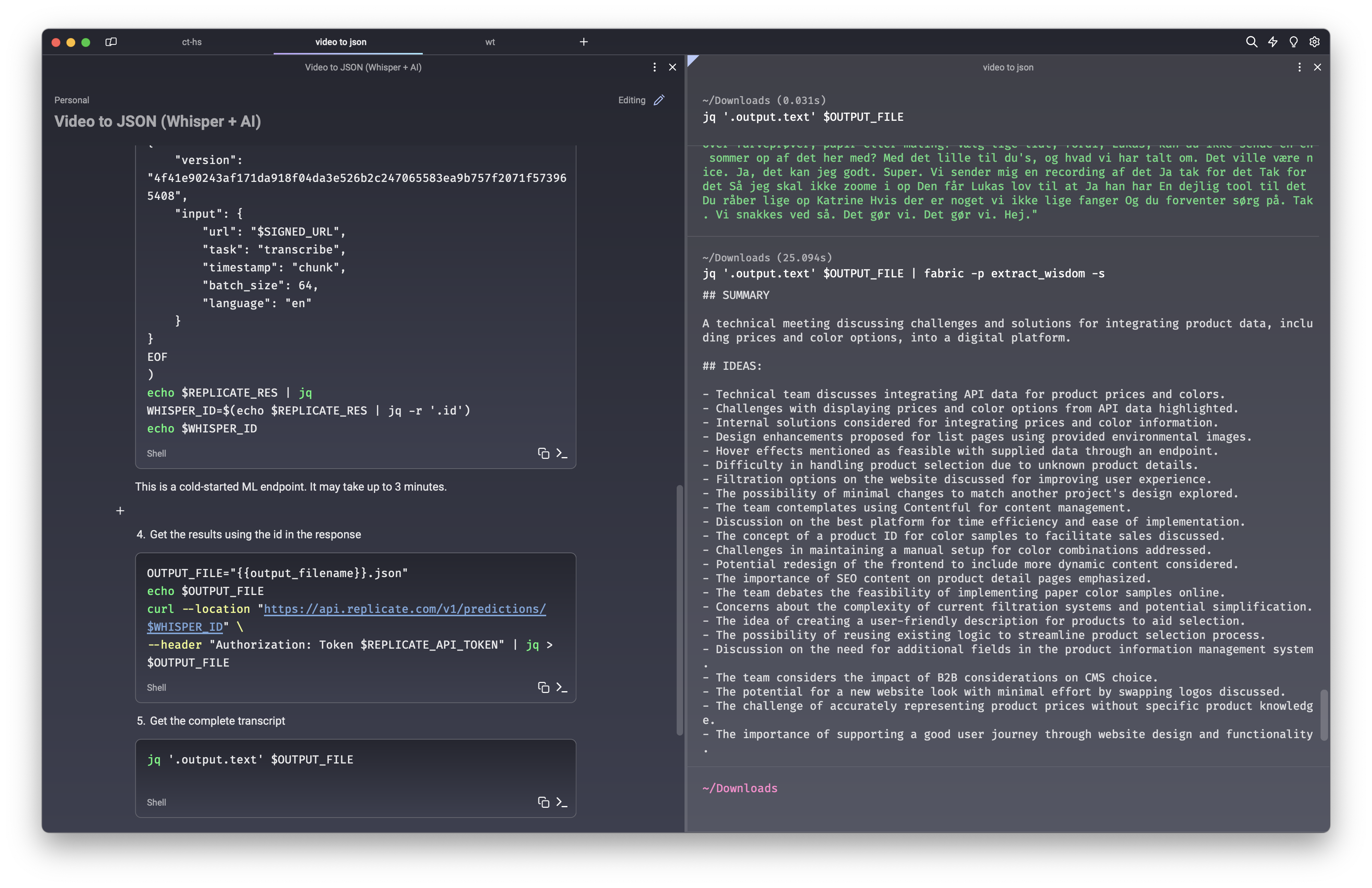
curl --location "https://api.replicate.com/v1/predictions/$WHISPER_ID" \
--header "Authorization: Token $REPLICATE_API_TOKEN" | jq > $OUTPUT_FILE
- Get the complete transcript using
jq
jq '.output.text' $OUTPUT_FILE
Bonus: Use AI to summarize
This is an example of how we could use AI to extract key points. I am currently using Fabric by Daniel Miessler repository. In short it provides a set of convenience prompts to submit together with the input text, that can be accepted as a piped input, while not leaving the terminal.
One of my favorite is extract_wisdom which was designed for YouTube videos.
jq '.output.text' $OUTPUT_FILE | fabric -p extract_wisdom -s