Building AI Automations with n8n
My humble notes from pioneering the AI Engineer position at the Joe & The Juice company
I've discovered coding back in 2013 and three years later I spent all my summer building my first Laravel app which is still in production by the non-profit I've built for.
Now I'm struggling to find the balance between enjoying the power of "I can build this myself" and not chocking myself to death trying to build everything myself.
As it is common for developers to be less articulate, I decided to leverage writing about my endeavours, to keep me up.
Preface
It is funny enough that I feel like I have to say that I hate writing and I am so happy that I finally sitting down and typing out these first words.
Back in 2025 I had a big burnout and several good things came out from it. One of them is that in the late autumn I transitioned from a full-time developer behind a legacy application to pioneering the AI integrations and automations at the juice company.
Many laugh thinking that I joke when I say I do that because "why would a food company need AI" which is quite funny because it might the type of a company that can benefit the most.
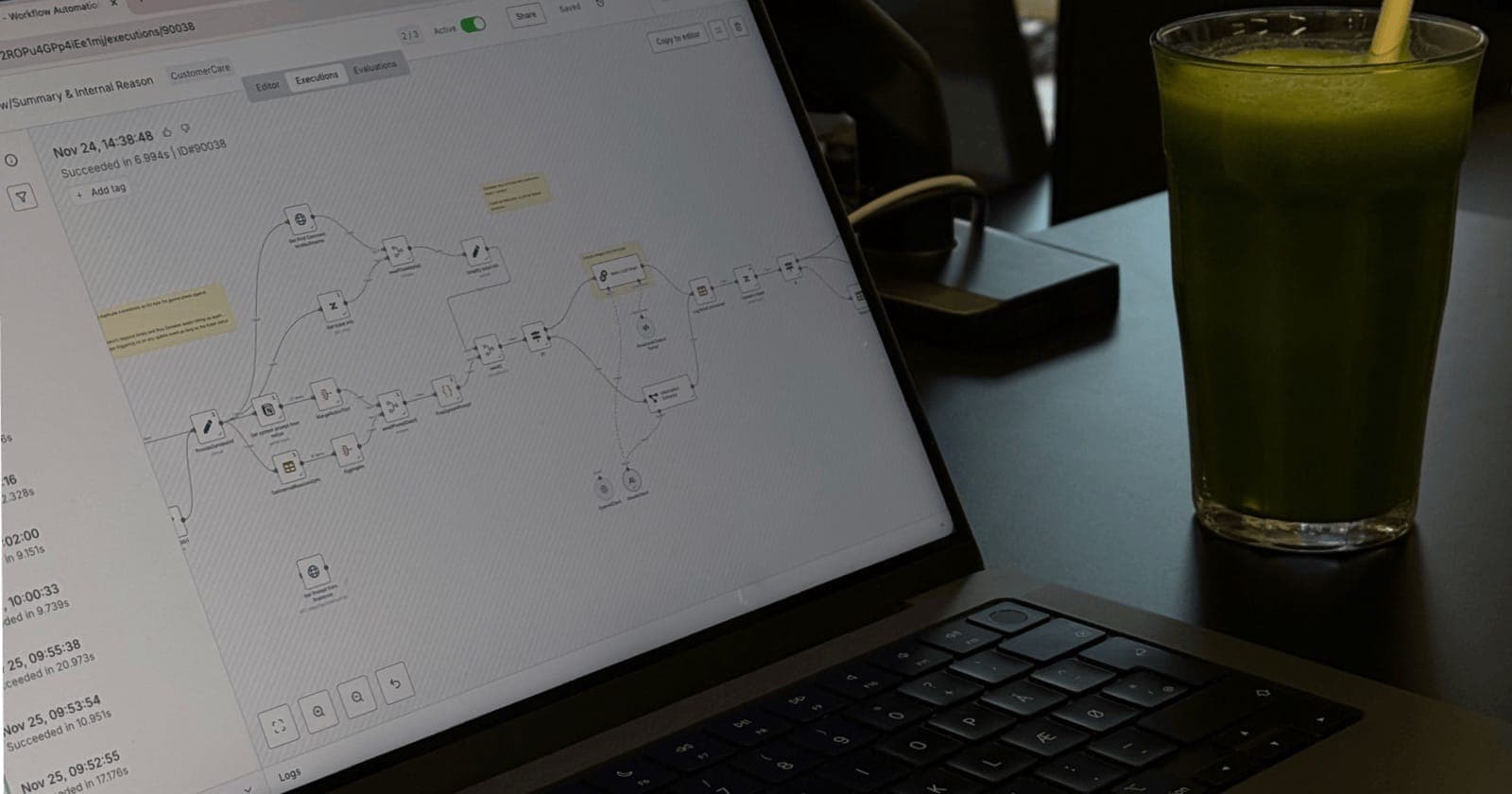
I have been building various workflows with n8n since October and it has taught me a lot. I have done several things with AI so it was not a complete new thing but there were many new learnings and I am excited to share them with you in my diary.
Steep learning curve with n8n
n8n is a more technical automation/integration platform, similar to make.com or Zapier however allowing to dive deeper with the code blocks and data mutation outside the predefined generic nodes.
I am as much of a developer as one can be. I seriously got into it when I was 16 years old when I was determined to use my summer vacation to build a web app - I did it. I love writing code because it's a first language to me and it feels so natural. That is not how I felt with n8n.
It required my brain to sweat quite a bit. There are many subtle pitfalls that only reveal themselves once you start building real workflows. There are probably countless of videos on the YouTube and articles out there teaching about those and I may have happened to skim through those parts. Maybe not. I will share some of those learnings here on my blog.
The biggest change is that in the code, let's say JavaScript since everyone is familiar, it is super easy to control concurrency. One either awaits one function or promise, or entire group of functions/promises. One explicitly defines where the data flows and what is returned. One can optionally enrich the data or flow via one or the other function without cracking the head. This is not so easy in n8n. Here are a few examples.
Few pain points with n8n workflows
Return data
Vertical order in n8n does matter, if there are two final nodes in the sub workflow and the one you don’t care is below the one you do care, it will output the wrong data. I would love that for enterprise approach one could explicitly select which return node is the actual return node and not depending on the order hierarchy.
The entry point is easy, the return is easy if there is only one node. However a good practice is to use the Execution Data node which lets you annotate your execution with various parameters - amazing for debugging. Now you have two nodes that are end nodes. The return data from the sub-workflow execution will be from the one that is the bottom-most. There is no explicit way to tell that in n8n. This makes me question whether n8n is truly enterprise‑ready in its current form. Big gotcha.
Nodes in n8n execute from left to right and from top to bottom. There also isn't any real concurrency if the parent execution wants to keep the track of. Meaning it's always left top to right bottom.
This bit me quite a lot. I feel itchy like after feeding an army of mosquitos in nature. I love converting bigger chunks of the workflow to a sub-workflow as soon as it makes sense to reuse or a soon as it logically means it can be encapsulated.
Be generous with logging
Debugging can be very cumbersome. I wish I could plug the errors to Sentry via some native connector but unfortunately that doesn't exist out-of-the-box.

Using the aforementioned Execution Data node is a must. In this node I always log the primary ID of the item I am processing. Such as Zendesk Ticket ID for the tickets there or the internetMessageId for the emails in Outlook.
Besides that I log extra information that I believe would make sense. Such as if your workflow has several branches (think processing extra images if exist) and whether this workflow has run that branch. You can have as many nodes along the workflow as you wish to enrich it.
One self decides on that. However searching for executions and filtering by the id is a game changer.
Do not use Cmd + Z (or Ctrl + Z) // Undo more than once
This is why I love computers. This is such a treat that one can try, go back and redo. People in sales, in medicine, in buildings can't quite do that. Fuck around and find out is how I got in my career where I am.
However NEVER click too many times Cmd - Z after dragging things around. My entire workflow got broken several times. I ended up experiencing vague execution errors saying the node doesn't exist or the data is wrong while iterating in the development. Downloading and re-importing the workflow or copying the nodes to another didn't help.
I had to go almost node by node in a new workflow and rebuild it from scratch. Now I fear the Undo like touching the hot pot.
No first party nodes for tracking the AI usage, tokens, or raw responses
This is huge. If not AI, n8n would be a small kid playing outside with anyone barely knowing its name. AI enabled people to build mini automations augmented with LLMs that bring enough value for it to blow up.
Crafting workflows in the enterprise, ideating, iterating and prototyping, for someone with ML training background, is a no-brainer to log the input/output for the AI that later can be used for Evals, for fine-tuning, for error or cost insights.
To this day, using the latest version at the day of writing, there is no node or clean way to store ai exchanges.
My first solution was to call the LLM node such as Claude to ClaudeAiClient and have sub workflow execute after the parent finishes (with no await for completion). The sub workflow would then retrieve the execution, find the *AiClient node and extract the messages and store to the database. This way I had exact tokens, raw messages and everything one would need.
Eventually our workflows have evolved a lot and due to other things I won't discuss here, I gave up on that detail logging and now just store the clean output in the main workflow.
I dream that n8n would add a final node that allows to retrieve all ai exchanges for sub nodes and let us handle the data how we wish.
Enterprise loves to answer the question how much does classifying the tickets cost? Okay, does it bring enough value to pay for them? How about the writing the response? How much does that cost? Oh that is 10M of tokens a day.... You get the gist.
The pleasure points with n8n
I had to get my complaining out of the way so I can focus on the pleasure. The n8n is an amazing platform for prototyping once the steep curve is ironed out.
Quick iteration
A lot of these workflows are novel. AI is still novel. Less than 3 years ago we heard about GPT 4 coming out which was slow and stupid. Now I trust ChatGPT to do my SKAT book keeping because it's that good at deep research and comprehension.
Same applies in the corporate. We know that we want the help at X department by doing Y. But the stakeholders don't necessarily know all that it takes and most importantly all that it takes they do implicitly. It is such an important thing that applies to us all.
If I say I am gonna eat an apple, I will implicitly wash the apple and wash my hands. I will also take the knife and cut the apple to slices because I wear braces. Think about this. There are many more steps and conditional processing. If one has braces on - the apple needs to be cut. If the email has big and many attachments, they need to be pre-processed before the AI can read the email and take a decision.
The hard thing here is that often some of these steps are only discovered once the thing is running. Walking up with the laptop to review the workflow with a non‑technical stakeholder and looking at the outputs at various stages - is like fine‑tuning a radio. It becomes visual, intuitive, and collaborative. That's a big plus.
Various Trigger nodes, aka integrations with platforms
Even though I still want to write code for some of these, having the built in triggers such as Zendesk for new incoming tickets, it's a bliss. I don't need to deploy the code to the cloud, I don't need to go in the Settings and register the webhook, I don't need configure credentials (besides putting ones in the n8n for the node). It just works, most of the time.
The gotcha here is that one has to be careful of the events. Too many executions and one can blow away through the monthly allowance. So be careful. Otherwise, it is a bliss to iterate with that.
I have done some funny stuff with my own Strava, an app for storing the runs or bike rides.
The greatest benefit of building these automations
Documentation.
Despite the common questions such as are we now trying to replace people with AI. In my case and journey - absolutely not.
However what I really love about building these workflows is how much implicit documentation comes out. I am now working with three prototypes for the support center and handling a shared mailbox. Since the first run of the automation, I've spared a lot with my colleagues to improve and explain AI (aka: write the system prompts) what, why and how should XYZ be done. Ever since, AI has caught up by catching human error where the people at question don't follow their own rules or things they explained. That means two things - they didn't tell everything at first because for us humans, things become a reflex muscle that we perform subconsciously and others, we actually just forget and do a mistake based on the moon phase.
Thanks to these workflows, I have some of the best documentation for certain touch points than any other departments because if this is not the "best", it won't perform its duty and deliver the value.
AI cannot be trusted
This is the final point that I feel is very important to note down. The enormous amount of hype being pumped on a regular basis by the major LLM developers (OpenAI, Anthropic, Google) as well as the entire AI Agency community and SaaS builders is insane. My former manager and a friend has caught me stuck in that bubble back in 2023. Now around three later, AI is a helpful tool but it fails in ridiculous ways.
Once every a few hundred executions given the task where it must output structured data with two fields - a string reasoning field and an integer correct_output field being - a union of either 1 or 2 - it will output 0 or 3. This is easy to show, but the funny/sad part is where the reasoning above is correct and the model still produced the wrong choice despite its own very reasoning.
Model in question has mostly been Claude Sonnet 4.5. The temperature by default is 0 aiming for the most consistent predictable outputs. The tricky part is that rerunning the same input will not cause the same error thus rendering any debugging basically useless. If it failed with illegal data? Simply rerun.
I have a few more examples that I will share in the future articles but this I find to be so small and so trivial task that it should never fail, in my perception.
Final remarks
I envision writing at least two more posts, based on how in-depth I am allowed to dive with the things I am engineering at the sandwich and juice company. One of them is about handling a shared Outlook Inbox that receives as many 5000+ emails a week, of which majority need to be accurately classified and stored, and a minority requires the human in the loop. The other being, classification and assistive reply support for the Customer Care on Zendesk system. Both are very interesting cases and have some exciting learning. Both have been running for several months and both departments are accustomed to have it running now.
If you're a human and read this far, I'd love to hear from you in the comments - are you exploring to use n8n? Are you evaluating the entire automation industry? Are you just learning? Or are you a seasoned hacker/tinkerer like me? :)